Hello,
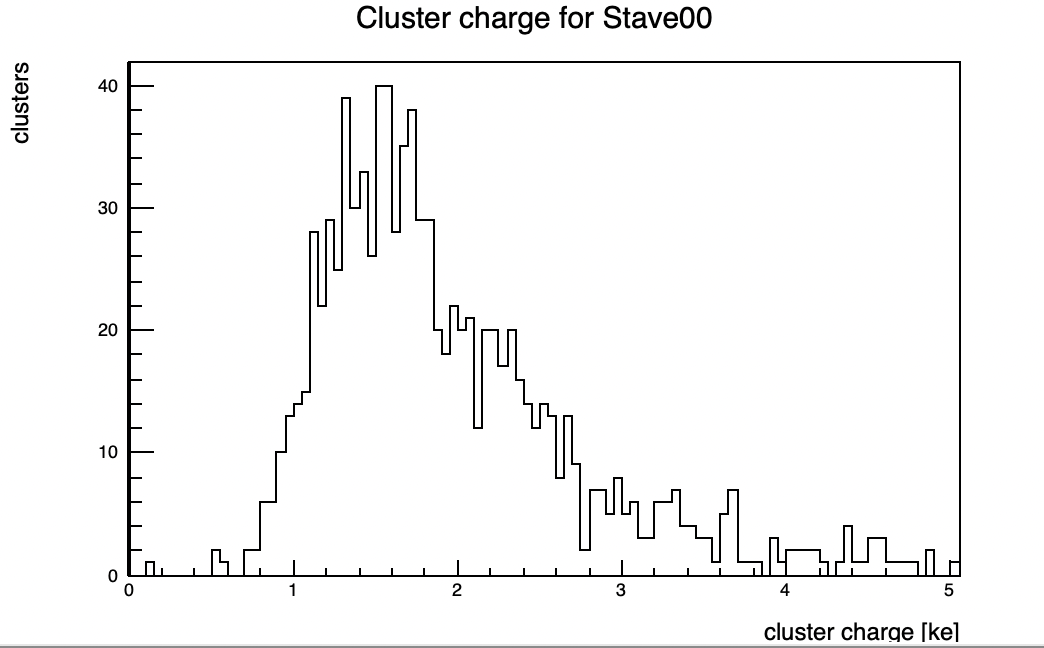
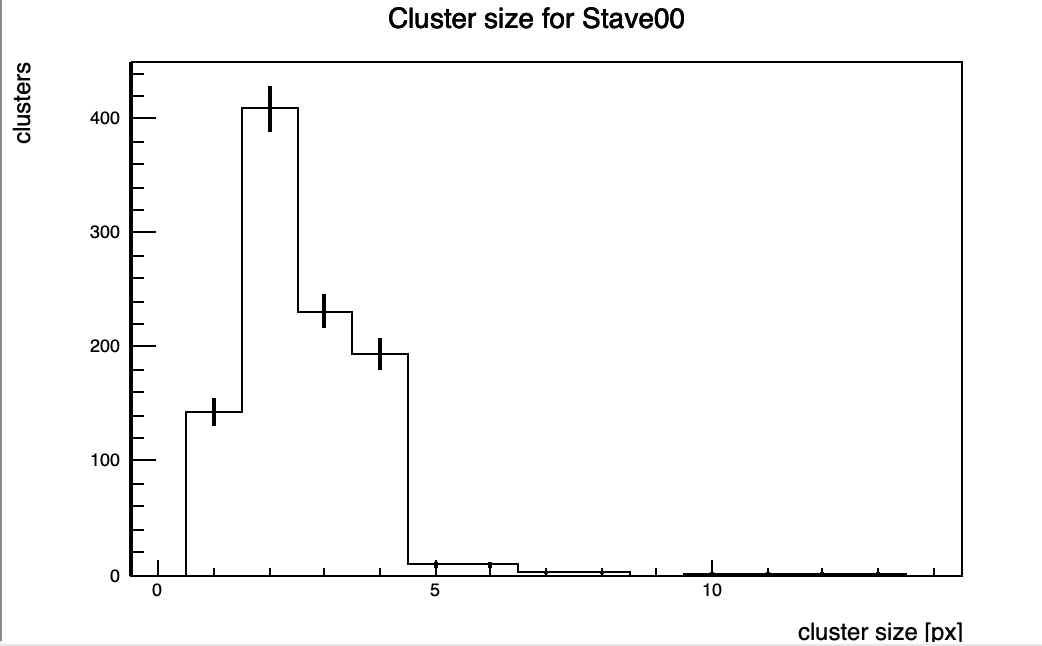
I am trying to compute the cluster charge and cluster size from the pixel hits on the ALPIDE chips. I like to prepare plots like these from the data.root files:
Following the manual, I looked at this code which prepares the ‘clusters’ tree.
I see that this code produces the total number of clusters in an event here, but I fail to see the size of individual clusters in the event. How do I prepare clusters from the PixelHits tree? Is there any default algorithm that Allpix2 already uses? I see something here, but not sure how to implement this for data.root file.
In the last part of the code, I see that the residual in x and y are prepared, but again this is one number per event. How do I make a distribution of residuals from clusters?
I have to admit that the code you quote does not really do a clustering, but it uses the assumption that all PixelHits in an event belong to the same cluster and just adds all of them, which is of course not always correct. The code in this directory is more to give an idea of how one can access the data, so it might actually be misleading.
Yes, there’s an algorithm that Allpix Squared uses, which is there to generate some useful plots in the DetectorHistogrammer. Now, the thing is: a cluster is already a step into a “data analysis”, which is not the goal of Allpix Squared. This is why storing clusters to ROOT files is intentionally not supported.
This means, that if using the plot of the DetectorHistogrammer is not sufficient and a further analysis of the simulated data is required, I suggest two options:
Implementing an algorithm like the one starting here for the post-processing. It groups adjacent PixelHits into clusters, which is of course better than simply taking all hits. You could e.g. port the method to python and use the script like the one you quoted.
Using an analysis framework to do the clustering for you. We work a lot with Corryvreckan, for which Allpix Squared actually has an interface. Meaning, you can export data to the corry file format and then load it using corry, which can perform a clustering and many more steps.
If you happen to take e.g. the clustering algorithm from the DetectorHistogrammer module and port it to the analysis script (or into a separate analysis script) we’d be more than happy to take that as an example into the repository for other people to use.
Also, we’d still love to add your ALPIDE simulation with the electric field function you presented at the workshop as an example to the repository.
Please let us know if we can assist you in any way to make that happen!
Hi @pschutze and @simonspa,
Many thanks for the heads up. If I want to implement doClustering function in the analysis script, do I have to import PixelHitMessage from here? What would be the easiest approach to implement this in the analysis code? I am particularly interested to know how I access the Event pointer and the messenger_ variable from the analysis code.
If I finalize the implementation of this clustering algorithm to the analysis script, I will be happy to share that with the Allpix-squared. For the custom electric field in ALPIDE simulation, this is still a work in progress and we cannot share this as of now. Once things are ready, we may share that with the team.
Unfortunately, the Event object (and therefore the messenger_ object) are only available during the simulation as these do not represent actual information but are technicalities of how the framework distributes the event simulation to different workers. Why do you need access to them?
Hi @simonspa ,
I tried to implement the doClustering function in the analysis script. You can see this part of the code.
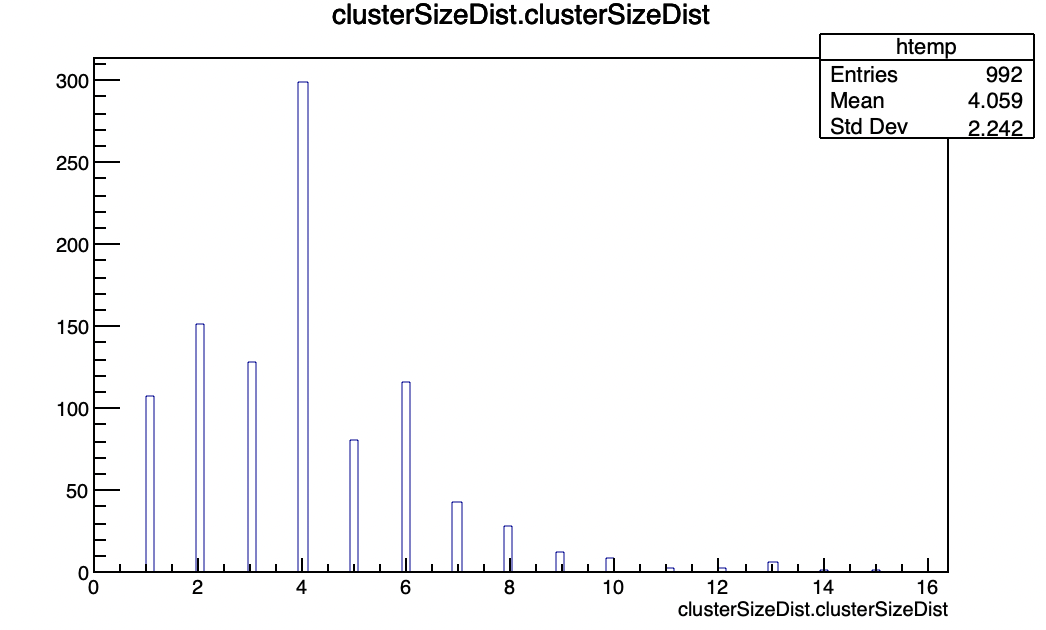
While the code is compiling and running fine, I see that the produced clusters are different in distributions compared to the histograms. For example, this is the cluster size distribution from the modules.root (using the DetectorHistogrammer):
The shapes are similar, but the normalization is different. I suspect in my code, I am double-counting some of the clusters, but could not figure out the problem. If you can have a glance and help me debug, that will be great.
You tried to simplify the original code but changed its meaning. In the original code we use iterators to loop over the vector, so we can use summing operations to move back and forth in the vector. You are using references to the vector elements on which you cannot just add 1 and expect to get the next pixel hit.
If you run root -x constructComparisonTree.C+ does it even compile?
Hi @simonspa ,
Thank you for pointing out the mistake. I have now modified the code to use iterators as suggested by you. Yet, I still see the cluster overcounting. I may be doing something very naive, pardon my ignorance. Any suggestion to write the code in a fruitful way?
that’s unfortunate. I would recommend to apply the same techniques as in the lab - try to reduce your problem to the minimum, e.g. by looking at only one or two events - both in the DetectorHistogrammer (log_level = DEBUG is your friend here) and in your own analysis and to compare what they do differently and which clusters they are finding.
Hi @simonspa ,
I have solved the cluster overcounting issue. It was just a silly bug of not properly clearing the vector in the loop. The updated code is this. Now I am trying to calculate the residual for each cluster. To do that, I want to know:
Is it possible that I do not hardcode the pixel pitch like this? In the DetectorHistogrammer module, I see that the pitch is taken from the detector model (here). Is it possible to do something like this in the root analyzer macro?
Particle position in DetectorHistogrammer takes into account the track smearing. What is this event->getRandomEngine() doing? Just a random number to shift the dx and dy? Can I replace this by simple TRandom functionality of root? I just want to make sure I am not misunderstanding something.
I am trying to use the allpix::Units::convert function (here). But I get the following error:
Error in <TRint::HandleTermInput()>: std::invalid_argument caught: unit um not found
event->getRandomEngine() gives you the pseudo-random number generator that should be used for exactly this event on this thread. This is necessary to maintain strong reproducibility (always the same outcome no matter how many workers or which machine). For your matters: yes, it is a PRNG that gives you a random number to shift x and y.
If you really need to use units in your analysis script (not sure about that) you nee to register them first: